Databricks Integration
Integration of Databricks with Entropy Data.
When setting up an integration between Entropy Data and Databricks, we provide two options:
1. Ingestion-based Integration (Built-In)
The integration is managed within Entropy Data. Configure the connection and sync schedule to start syncing with Databricks.
No additional deployments are needed.
2. Connector-based Integration
Our connectors are based on the Datamesh Manager SDK and provide support for more use cases. You get the asset syncing capabilities of the ingestion-based integration, plus direct integration with Databricks permissions. Changes through the Access Approval Workflow can be dynamically applied to Databricks user permissions.
If you have a complex network topology or direct integration with Entropy Data is not possible due to governance restrictions, the Databricks connector can be deployed in a DMZ of your network to provide additional security.
| Feature | Ingestion-based Integration | Connector-based Integration |
|---|---|---|
| Direct integration into Entropy Data | ✅ | |
| Syncing of assets | ✅ | ✅ |
| Syncing of permissions | ✅ | |
| Complete control of deployment | ✅ | |
| Support for different network topologies | ✅ |
1. Ingestion-based Integration
You can directly integrate Databricks with Entropy Data.
Prerequisites
You need an Entropy Data Enterprise License or the Cloud Edition. To enable the integration, set APPLICATION_INGESTIONS_ENABLED to true in your environment. See Configuration for more information.
To start, navigate to Settings > Integrations > Add Integration.
This opens a wizard that guides you through configuring the integration.
Select the Integration Type
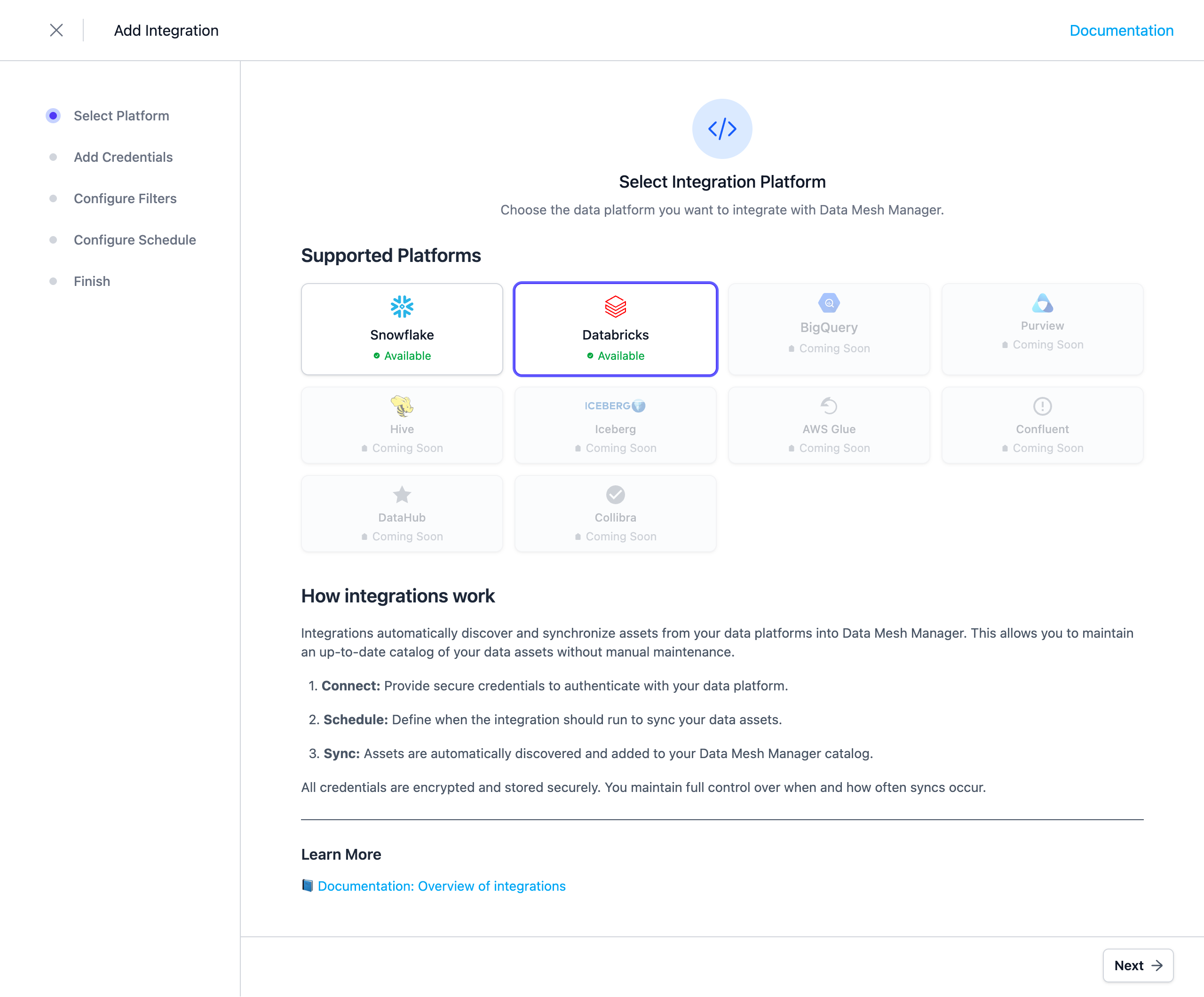
Configure the Credentials
The integration uses OAuth for service principals as authentication method. Refer to the Databricks documentation for adding a service principal to your account and obtaining an OAuth secret.
Note: Credentials are stored encrypted in the Entropy Data database. To enable encryption in your environment, set a 64 hex character
APPLICATION_ENCRYPTION_KEYSin your environment (see Configuration).
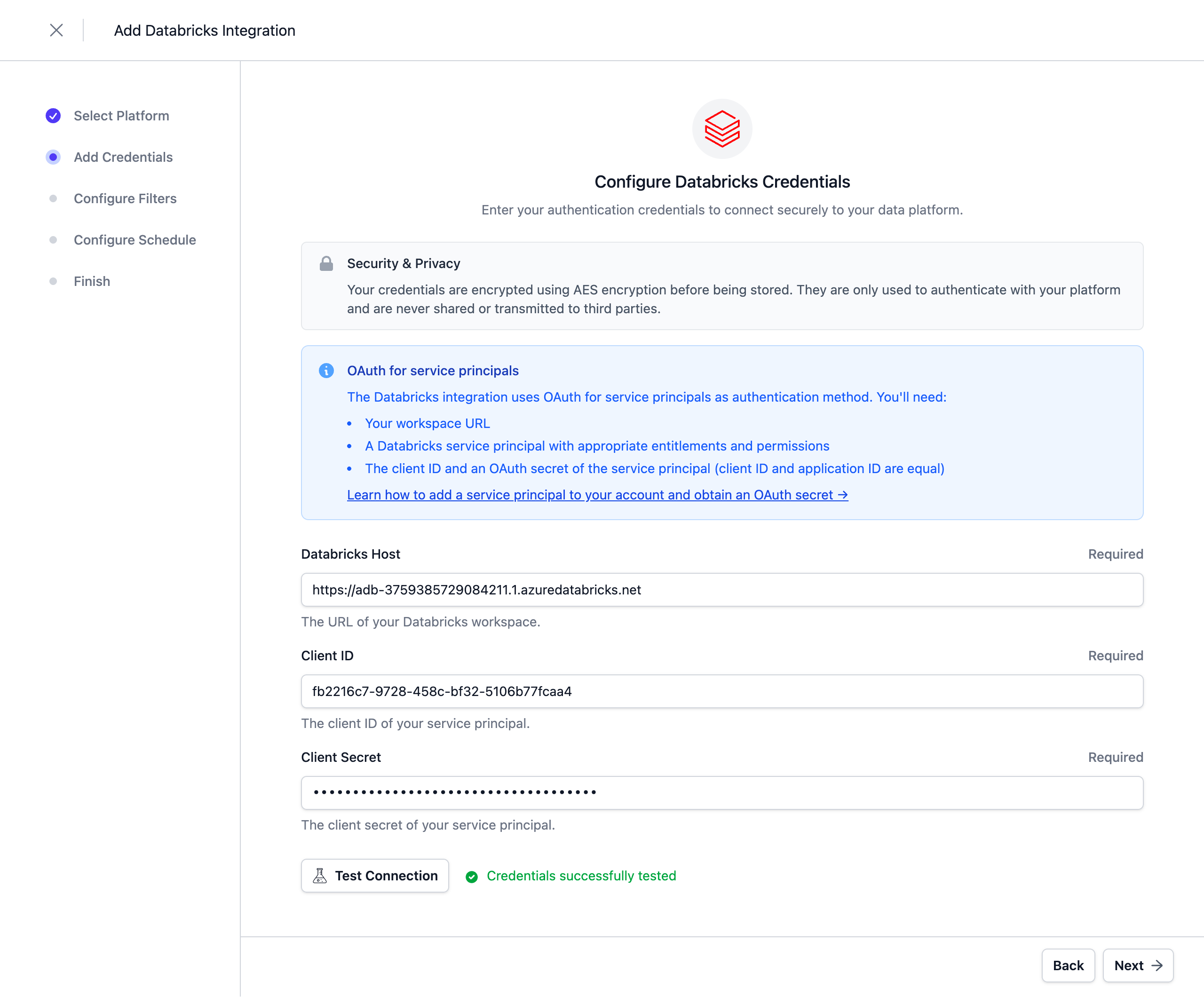
Configure Filters
Configure filters to limit which assets are synchronized. Both include and exclude filters are supported. For Databricks, filters can be applied to Catalogs, Schemas, and Tables.
Filters support '*' as a wildcard character to match any number of characters.
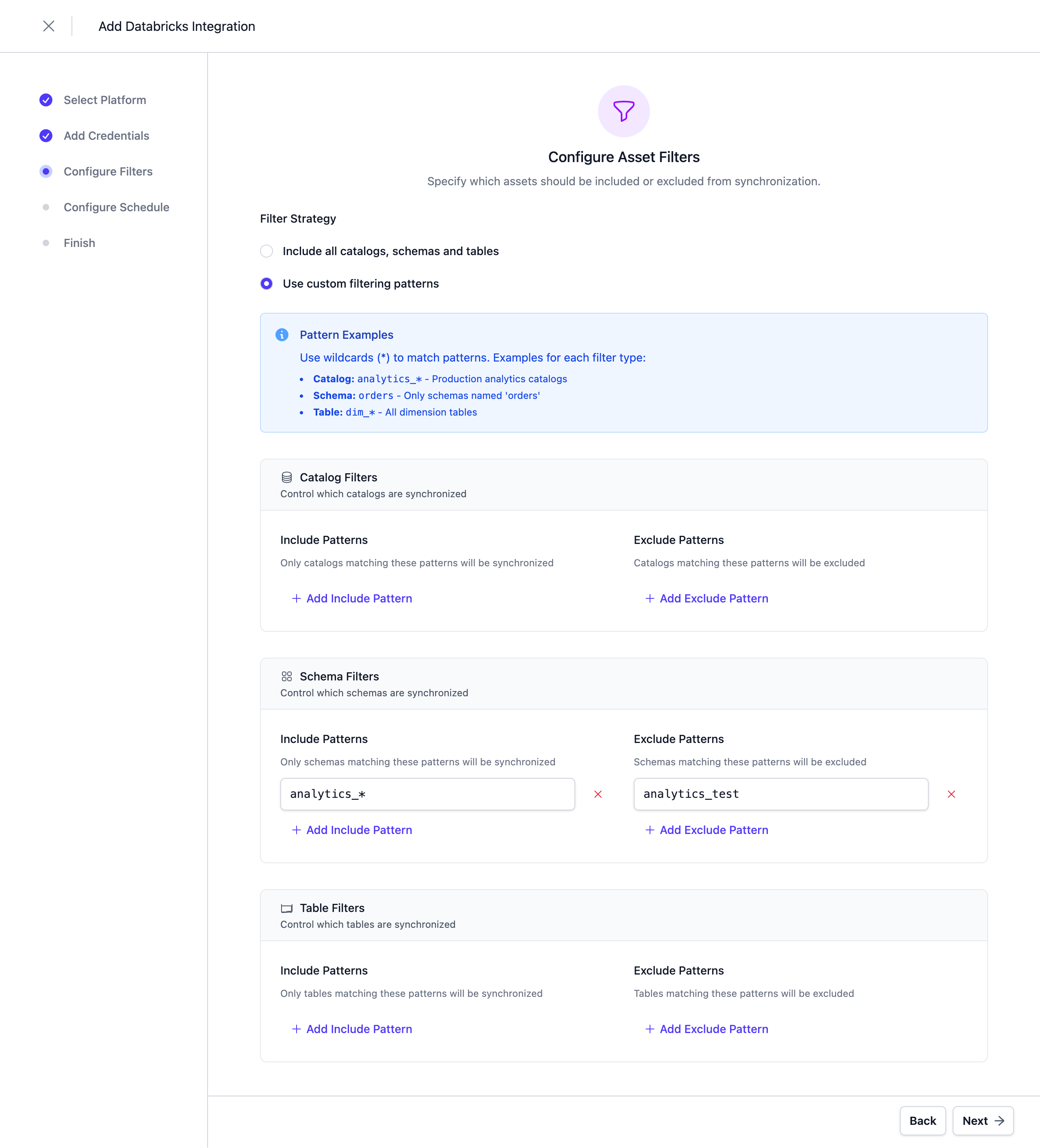
Configure Schedule
Set a schedule to automatically synchronize assets. You can choose from predefined schedules or define a custom schedule using the cron expression format.
Note: All schedules use UTC timezone, so make sure to take this into account when configuring your schedule. Please do not synchronize the assets more than once or twice per day. We reserve the right to disable the integration if this happens. You will be able to trigger a synchronization manually if you need an immediate update.
Complete the Integration Configuration
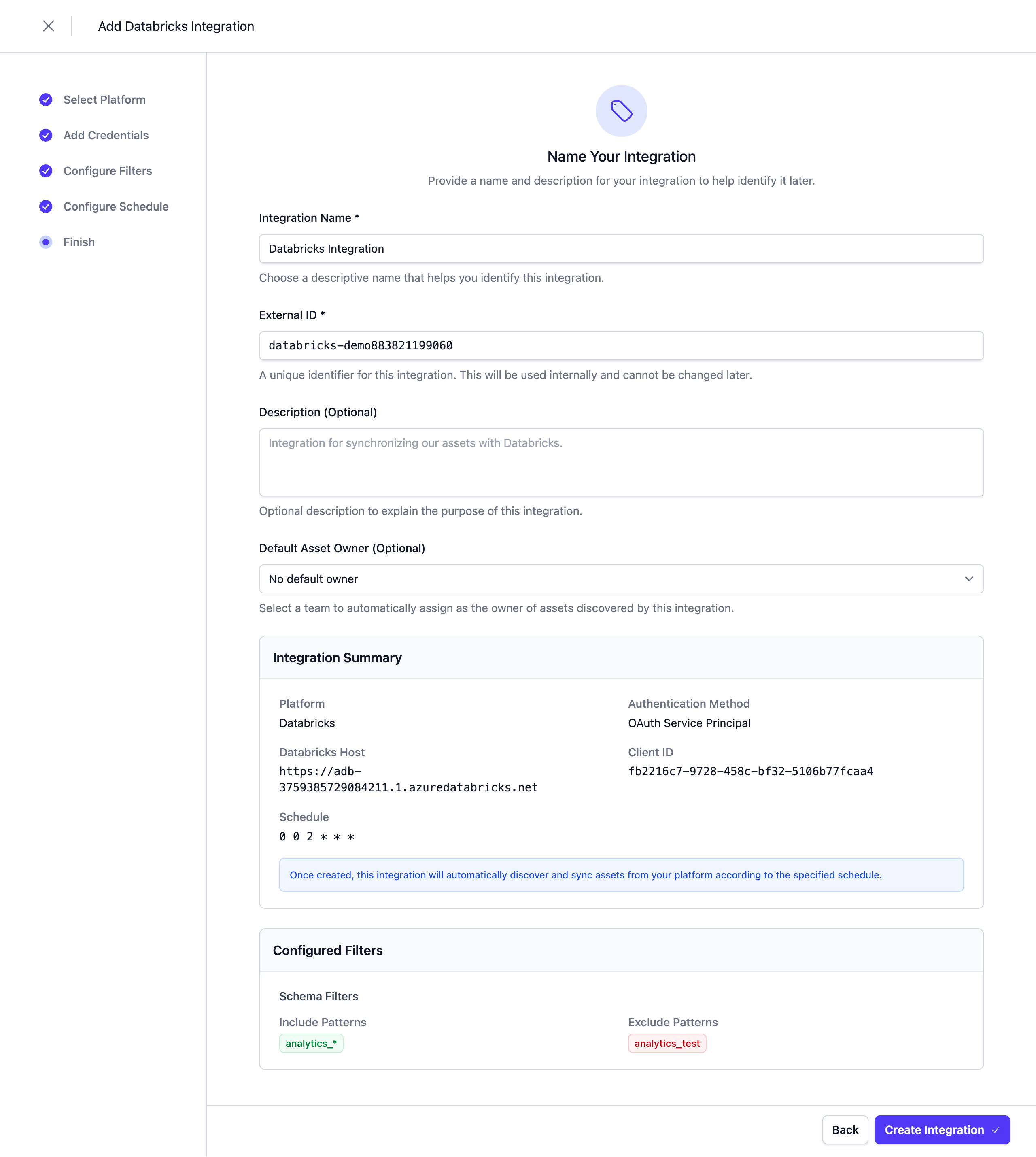
Choose a unique name for the integration, review your configuration, and click Save.
Next Steps
The integration is now configured and will run according to the schedule. To check the integration status, navigate to Settings > Integrations. Here you'll find the current status and the last 10 integration runs.
You can adjust the integration configuration and credentials at any time. The configuration is saved in YAML format with syntax validation support in the editor.
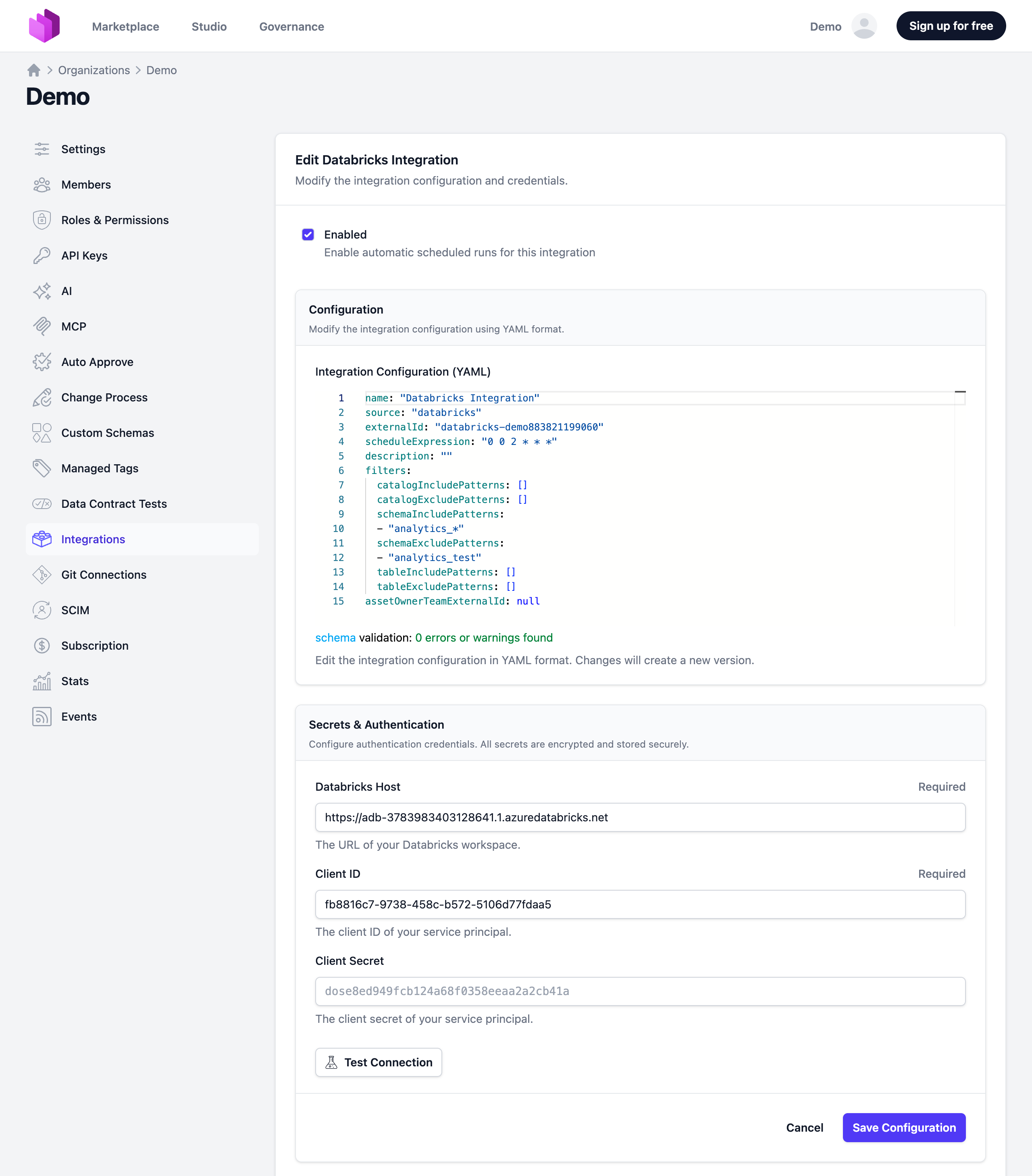
Note: The previously stored client secret is not displayed in the edit view for security reasons.
Deselecting the Enabled checkbox disables the automatic schedule. Manual integration runs are still possible.
2. Connector-based Integration
The Databricks Connector is an open-source component that integrates Entropy Data with Databricks. It is based on the SDK and available as a Docker image. The source code can be forked to implement custom integrations.
Features
- Asset Synchronization: Sync catalogs, schemas, and tables from Databricks to Entropy Data as Assets.
- Access Management: Listen for AccessActivated and AccessDeactivated events in Entropy Data and grant access on Databricks to the data consumer.
Links
- Source Code: Entropy Data Connector for Databricks on GitHub
Databricks Asset Bundles
Databricks Asset Bundles (DABs) provide a standardized format for bundling data products on Databricks. They contain all necessary files to run a data product, including code and configuration. Our extended template builds on the standard open-source Databricks Asset Bundle template, adding Entropy Data integration that automatically registers the data product and its data contract via the REST API.
# Create a new Databricks Asset Bundle using the Entropy Data template
databricks bundle init https://github.com/datamesh-manager/databricks-bundle-python-template
Links
- Tutorial: How To Build a Data Product with Databricks
- Source Code: Entropy Data Asset Bundle Template For Databricks on GitHub